编码算法
Base58#
Base58是一种将非可视字符与可视化字符(ASCII)相互转化的编解码方法。实现了数据的压缩、便于阅读,适用于抗自动监视的传输系统的底层编码机制,但缺乏校验机制,无法检测出传输过程中字符串的遗漏,需要配合改进算法Base58Check使用。
Base58采用数字、大写字母、小写字母(去除歧义字符 0 (零), O (大写字母O), I (大写的字母i) and l (小写的字母L) ),总计58个字符作为编码的字母表。
Neo使用的字母表为:123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz
接口定义:
- 编码方法:把byte[]数据编码成Base58字符串String数据
string Encode(byte[] input)- 解码方法:Base58字符串String解码成byte[]数据
byte[] Decode(string input)编码步骤:
在 byte[] 数据前添加一个0x00,生成一个新的byte数组,并将新数组做反转操作
把数组的数据转成10进制BigInteger数
把BigInteger数按字母表转换成58进制字符串
统计原 byte[] 数据中0x00的个数 count,在字符串前补 count 个字母表游标为零所对应的字符
解码步骤:
将输入的字符串按Base58字母表转换成10进制BigInteger数
把 Biginteger 数转换成 byte[] 数据,并将 byte[] 数据倒序排序
统计原输入的字符串中字母表游标为零所对应的字符的个数 count
若 byte[] 数据的长度大于1,且 byte[0] 等于0,且 byte[1] 大于等于0x80,则从 byte[1] 开始截取,否则从 byte[0] 开始截取,得到结果。
Example:
| 字符串 | byte[] |
|---|---|
| NTRAJ9EEjHFHhHZvMKEKfkceg5V9ppx5ZP | [0x35, 0x52, 0x4e, 0x37, 0xb7, 0x01, 0x39, 0xc8, 0x96, 0xeb, 0xd5, 0x4a, 0x86, 0x48, 0xd3, 0xfa, 0x78, 0x6b, 0x26, 0x48, 0x76, 0xea, 0xc5, 0x26, 0xce] |
应用场景:
为Base58Check编解码方法提供服务。
Base58Check#
Base58Check是基于Base58的改进型编解码方法。通过对原数据添加数据的哈希值作为盐,弥补了Base58缺少效验机制的缺点。
接口定义:
- 编码方法:把 byte[] 数据编码成带校验功能 Base58 字符串 String 数据
string Base58CheckEncode(byte[] input)- 解码方法:把带校验功能 Base58 字符串 String 解码成 byte[] 数据
byte[] Base58CheckDecode(string input)编码步骤:
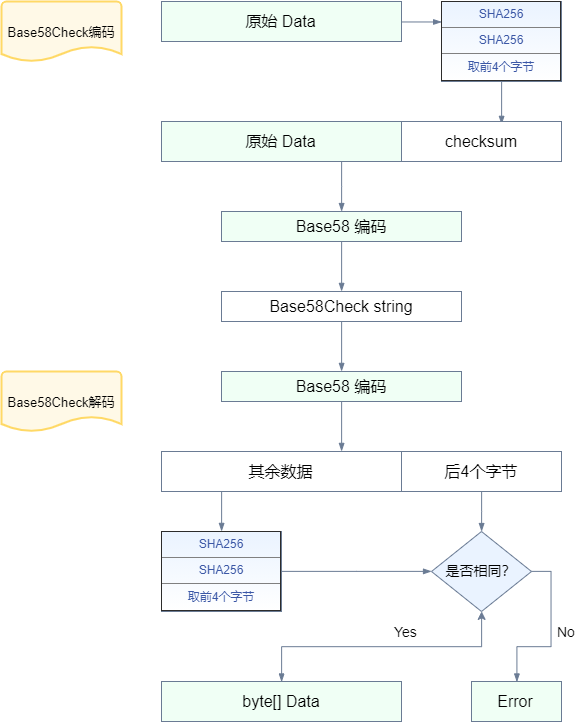
通过对原 byte[] 数据做两次 sha256 得到原数据的哈希,取其前4字节作为版本前缀checksum,添加到原 byte[] 数据的末尾。
把添加了版本前缀的 byte[] 数据做 Base58 编码得到对应的字符串。
解码步骤:
把输入的字符串做 Base58 解码,得到 byte[] 数据。
取 byte[] 数据首字节到倒数第4字节前的所有数据 byte[] 称作 data。
把 data 做两次 SHA256 得到的哈希值的前4字节作为版本前缀 checksum,与 byte[] 数据的后4字节比较是否相同,相同则返回data, 否则判定为数据无效。
Example:
| 字符串 | byte[] |
|---|---|
| NTRAJ9EEjHFHhHZvMKEKfkceg5V9ppx5ZP | [0x35, 0x52, 0x4e, 0x37, 0xb7, 0x01, 0x39, 0xc8, 0x96, 0xeb, 0xd5, 0x4a, 0x86, 0x48, 0xd3, 0xfa, 0x78, 0x6b, 0x26, 0x48, 0x76] |
应用场景:
导入、导出输出wif格式的密钥
合约脚本哈希与地址字符串相互转换
导入、导出NEP2格式密钥