Consensus Mechanism
Overview#
A blockchain is a decentralized distributed ledger system. It could be used for registration and issuance of digitalized assets, property right certificates, credit points and so on. It enables transfer, payment, and transactions in a peer-to-peer way. The blockchain technology was originally proposed by Satoshi Nakamoto in a cryptography mailing list, i.e. the Bitcoin. Since then, numerous applications based on the blockchain emerged, such as e-cash systems, stock equity exchanges and Smart Contract systems.
A blockchain system is advantageous over a traditional centralized ledger system for its full-openness, immutability and anti-multiple-spend characters, and it does not rely on any kind of trusted third-party.
However, like all distributed systems, blockchain systems are challenged with network latency, transmission errors, software bugs, security loopholes and black-hat hacker threats. Moreover, its decentralized nature suggests that no participant of the system cannot be trusted. Malicious nodes may emerge, so does data difference due to conflicting interests.
To counter these potential errors, a blockchain system is in need of an efficient consensus mechanism to ensure that every node has a copy of a recognized version of the total ledger. Traditional fault tolerance mechanisms concerning certain problems may not be completely capable of tackling the issue that distributed and blockchain systems are faced with. A universal cure-to-all fault tolerance solution is in need.
Proof-of-Work mechanism, employed by the Bitcoin, addresses this issue rather brilliantly. But it comes with an obvious price, i.e. significant electricity cost and energy consumption. Further, with Bitcoin’s existence, new blockchains must find different hashing algorithms, so as to prevent computational attacks from it. For example, Litecoin adopts SCRYPT, rather than Bitcoin’s SHA256.
Byzantine Fault Tolerance mechanism is a universal solution for distributed systems. NEO proposes dBFT (delegated Byzantine Fault Tolerance) consensus algorithm based on PBFT (Practical Byzantine Fault Tolerance) algorithm. Algorithm dBFT determines validator set according to real-time blockchain voting, which effectively enhances the effectiveness of the algorithm, bringing block time and transaction confirmation time savings. dBFT2.0 as an upgraded version was released in Mar. 2019, which improves robustness and safety by introducing 3-stage consensus as well as a recovery mechanism.
System Model#
A blockchain is a distributed ledger system in which participants connect with each other via a peer-to-peer network. All messages within it will be sent by broadcasting. Two types of roles exist: Ordinary nodes and Bookkeeping nodes. Ordinary nodes use the system to transfer and exchange, accepting ledger data; while bookkeeping nodes provide accounting service for the entire network and maintain the ledger.
Hypothetically, in this system, messages may subject to loss, damage, latency and repetition. Also, the sending order may not necessarily be consistent with the receiving order of messages. The activities of nodes could be arbitrary, they may join and quit the network at any time; they may also dump and falsify information or simply stop working. Artificial or non-artificial glitches may occur as well.
Integrity and Authenticity of information transmission are ensured with cryptography while senders must attach signatures to the hash value of the message sent.
The Algorithm#
Our algorithm ensures security as well as usability. With erroneous nodes in the consensus making no more than ⌊ (N−1) / 3 ⌋ , the functionality and stability of the system is guaranteed. In it, N = |𝑅| suggests the total number of nodes joined in the consensus making while R stands for the set of consensus nodes. Given F = ⌊ (N−1) / 3 ⌋ , f stands for the maximum number of erroneous nodes allowed in the system. In fact, the total ledger is maintained by bookkeeping nodes while ordinary nodes do not participate in the consensus making. This is to show the entire consensus making procedures.
All consensus nodes are required to maintain a state table to record current consensus status. The data set used for a consensus from its beginning to its end is called a View. If consensus cannot be reached within the current View, a View Change will be required. We identify each View with a number v, starting from 0 and it may increase till achieving the consensus.
We identify each consensus node with a number, starting from 0, the last node is numbered N − 1. For each round of consensus making, a node will play speaker of the house while other nodes play congressmen. The speaker’s number p will be determined by the following algorithm: Hypothetically the current block height is h, then 𝑝 = (ℎ − 𝑣) 𝑚𝑜𝑑 N, p’s value range will be 0 ≤ 𝑝 < N .
A new block will be generated with each round of consensus, with at least N − F signatures from bookkeeping nodes. Upon the generation of a block, a new round of consensus making shall begin, resetting v=0.
General Procedures#
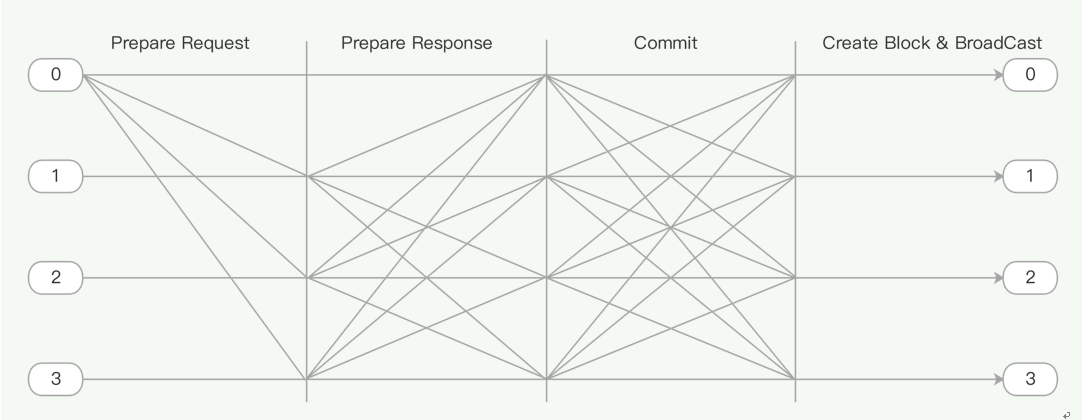
A round of consensus consists of 4 steps, as shown in the Figure above.
- Speaker starts consensus by broadcasting a Prepare Request message,
- Delegates broadcast Prepare Response after receiving the Prepare Request message,
- Validators broadcast Commit after receiving enough Prepare Response messages,
- Validators produce & broadcast a new block after receiving enough Commit messages.
View Change#
In case of the following scenarios, the Change View Request will be broadcasted attempting to replace speaker:
- The transaction verification fails
- Time is out while waiting for Prepare Request or Prepare Response
Recovery Mechanism#
When creating Change View Request, if there are not enough active consensus nodes (sum of nodes with Commit sent and fault nodes is greater than F), consensus nodes will broadcast Recovery Request message to update the local consensus context. Upon receiving Recovery Request, if certain conditions are met, a consensus node will generate and broadcast Recovery Message.
Fault Tolerance of dBFT2.0#
A dBFT2.0 consensus system with N validators can tolerate at most F abnormal nodes. Each consensus phase (Commit, Change View, block generation, etc.) requires at least M nodes to reach consensus. As long as the amount of normal validators is not less than M, the consensus process will go on smoothly. For example, just 4 − ⌊ (4−1) / 3 ⌋ =3 normal validators required can keep alive a consensus system where N = 4.
Single Block Finality of dBFT2.0#
Neo's dBFT 1.0 algorithm was susceptible to a single block fork in rare cases of network latency. dBFT2.0 fixes this problem, hence there is no possibility of forking since then. The mechanism is described as follows:
- To generate a new block, it is required to collect Commit messages from at least M different validators for corresponding block proposal.
- A validator will never change its view after broadcasting Commit message.
Hence the success of block generation means:
- There are already at least M validators having signed the block proposal and broadcast Commit messages. Moreover, these validators won't change the view in current consensus round.
- The rest of the validators are insufficient to produce another different block.
Therefore, the finality of the new block can be guaranteed at a given height.